
This study also calls out LM Arena for what appears to be much greater promotion of private models like Gemini, ChatGPT, and Claude. Developers collect data on model interactions from the Chatbot Arena API, but teams focusing on open models consistently get the short end of the stick.
The researchers point out that certain models appear in arena faceoffs much more often, with Google and OpenAI together accounting for over 34 percent of collected model data. Firms like xAI, Meta, and Amazon are also disproportionately represented in the arena. Therefore, those firms get more vibemarking data compared to the makers of open models.
More models, more evals
The study authors have a list of suggestions to make LM Arena more fair. Several of the paper's recommendations are aimed at correcting the imbalance of privately tested commercial models, for example, by limiting the number of models a group can add and retract before releasing one. The study also suggests showing all model results, even if they aren't final.
However, the site's operators take issue with some of the paper's methodology and conclusions. LM Arena points out that the pre-release testing features have not been kept secret, with a March 2024 blog post featuring a brief explanation of the system. They also contend that model creators don't technically choose the version that is released. Instead, the site simply doesn't show non-public versions for simplicity's sake. When a developer releases the final version, that's what LM Arena shows to users.
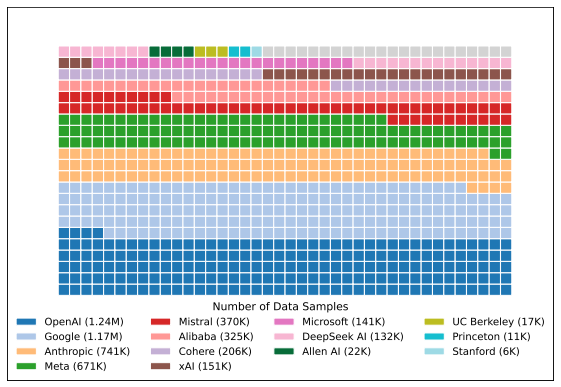
Credit: Shivalika Singh et al.
Proprietary models get disproportionate attention in the Chatbot Arena, the study says. Credit: Shivalika Singh et al.
One place the two sides may find alignment is on the question of unequal matchups. The study authors call for fair sampling, which will ensure open models appear in Chatbot Arena at a rate similar to the likes of Gemini and ChatGPT. LM Arena has suggested it will work to make the sampling algorithm more varied so you don't always get the big commercial models. That would send more eval data to small players, giving them the chance to improve and challenge the big commercial models.
LM Arena recently announced it was forming a corporate entity to continue its work. With money on the table, the operators need to ensure Chatbot Arena continues figuring into the development of popular models. However, it's not clear this is an objectively better way to evaluate chatbots versus academic tests. As people vote on vibes, there's a real possibility we are pushing models to adopt sycophantic tendencies. This may have helped nudge ChatGPT into suck-up territory in recent weeks, a move that OpenAI has hastily reverted after widespread anger.






0 تعليق